IMPORTANT: Please note that using AI-driven AFL Code Assistant requires one-time configuration of its "brain", large language model and the process is described later in this guide.
The Assistant is available as side window in the AFL Editor (you can show/hide Assistant window using Window -> AFL Code Assistant menu).
The Assistant window is divided into two parts
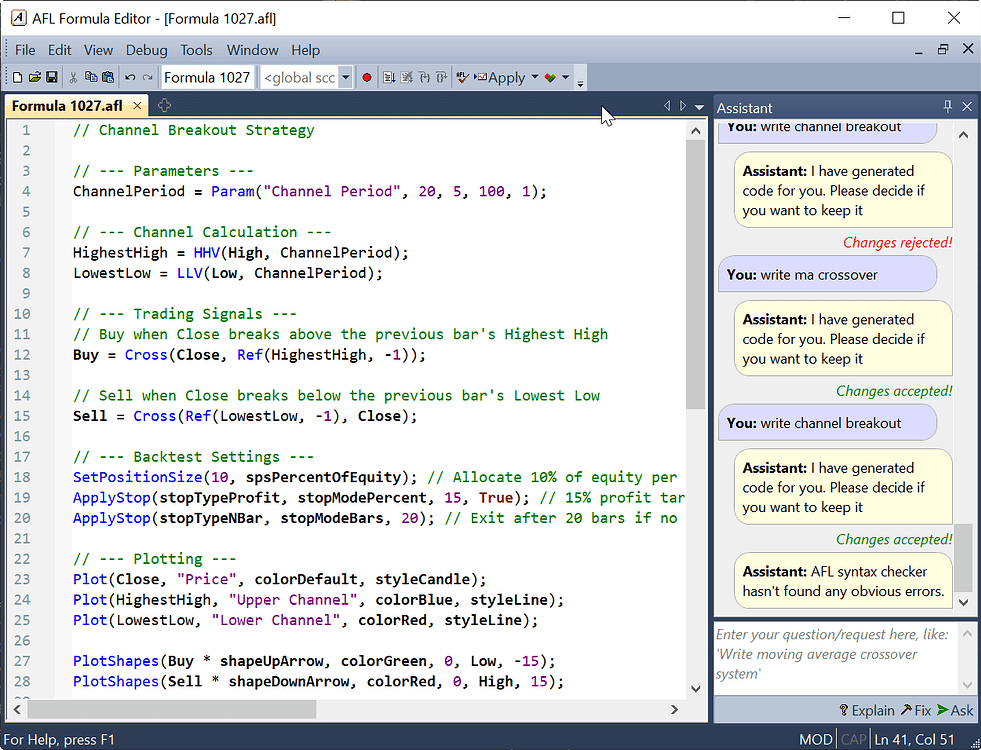
You don't need to be verbose in your request, the Assistant is smart enough to produce useful results with minimal prompts like "write channel breakout". The entire code that can be seen on the screenshot was generated in response to just this single prompt.
There are 3 basic actions that you do with the Assistant, represented by buttons in the bottom of Assistant window
Of course you can also ask any other question / give any other request. The Assistant may either generate code for you and offer changes, or it may generate textual response (like in "Explain" case) that is displayed in the upper pane.
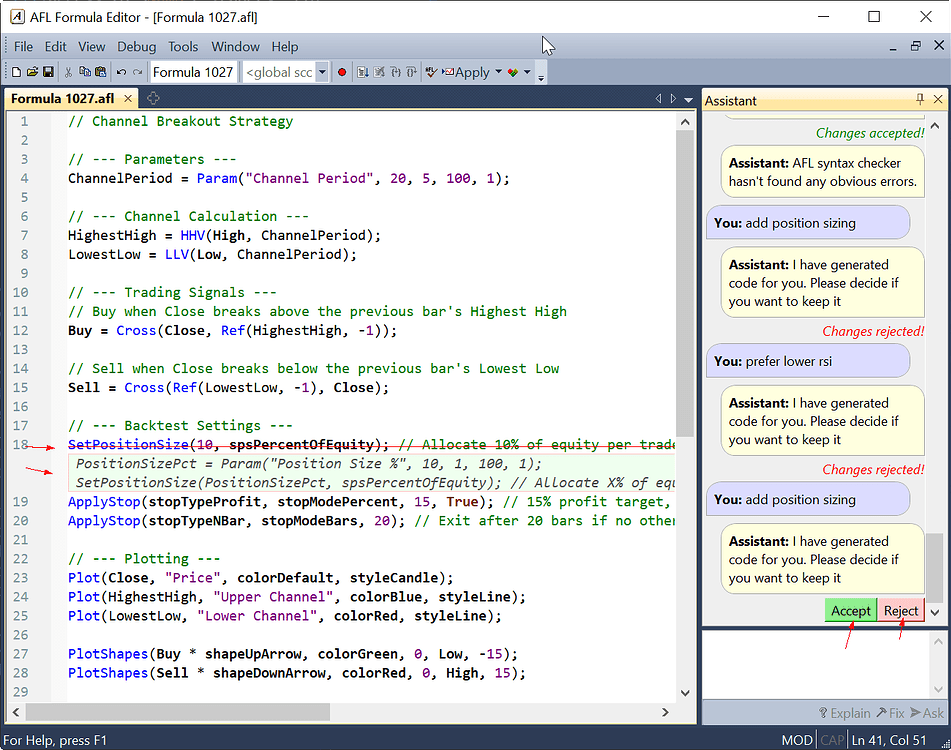
When the Assistant proposes changes in the code, it will display changes directly in the editor, new (added) parts will be displayed with green background and italic font. Lines that are to be deleted are stroked thru using red line as shown in the picture. Now it is user task to review and accept or reject changes using "Accept" or "Reject" buttons. Note that any manual edits done to the formula while wizard waits for you to decide, will result in automatic rejection of changes.
PRIVACY NOTE: by using Cloud AI services like OpenAI/Google Gemini, you will be sending your questions / requests and the formula that you edit to OpenAI/Gemini large language model for inference. Privacy-wise is not different than using OpenAI/Google web site directly. The transmission is secure and encrypted (via SSL/HTTPS), but obviously OpenAI and Google can see what you are sending to them.
PERFORMANCE NOTE Using cloud based LLM gives you access to state-of-the-art models that are much faster and much more capable than any local / open source model can be. The tradeoff is privacy.
Note: You won't be able to view this key again once you navigate away from the page.
Note: This key is essential for authenticating API requests.
PRIVACY NOTE: by using local private LLM, your requests and your code does NOT leave your machine. Everything is processed locally and nothing is sent anywhere.
PERFORMANCE NOTE Using local private LLM gives you maximum privacy but limits you open-weight models that are typically smaller and much less capable than state-of-the-art offered by cloud based services. Typically they are also much (10x) slower (when run on customer-grade graphic cards). To get any kind of tolerable performance you need dedicated graphic card (NVidia or AMD) with at least 8GB of VRAM (12GB of more preferred) that is needed to accelerate inference.
If you prefer not to rely on external APIs, you can run a local LLM using LM Studio.
127.0.0.1.1234.For detailed instructions, refer to the LM Studio documentation.
Open AmiBroker.
Navigate to Tools → Preferences → AI tab.
For OpenAI:
gpt-4.1-mini (we recommend this one for balance between cost and performance, but you can use any other)https://api.openai.com/v1/chat/completions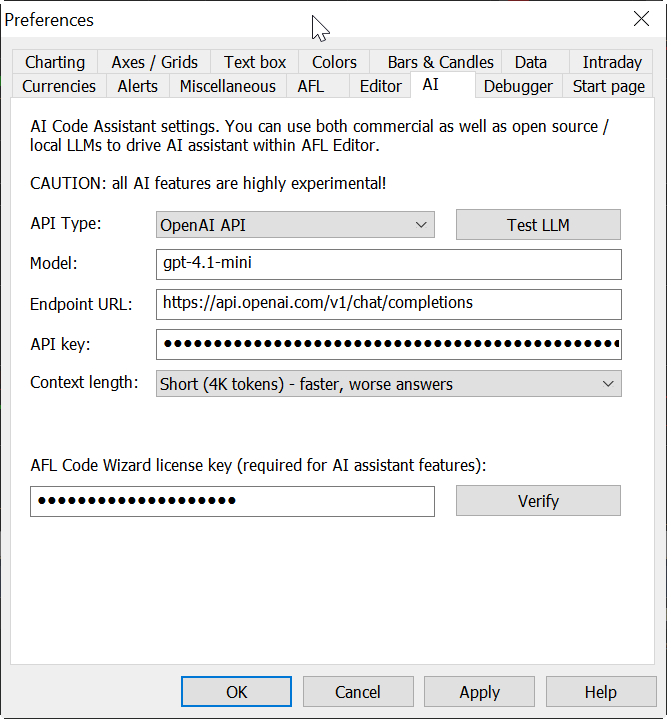
For Google Gemini:
gemini-2.5-flash (we recommend this one for balance between cost and performance, but you can use any other)https://generativelanguage.googleapis.com/v1beta/models/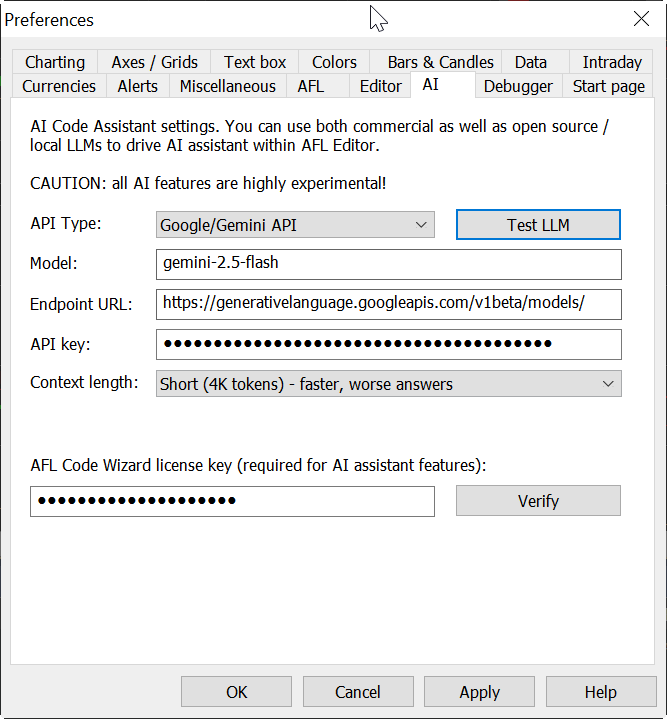
For Local LLM:
qwen/qwen2.5-coder-14b (this model we have been testing with, it works relatively good on 12GB RTX3060 or higher)http://127.0.0.1:1234/v1/vhat/completions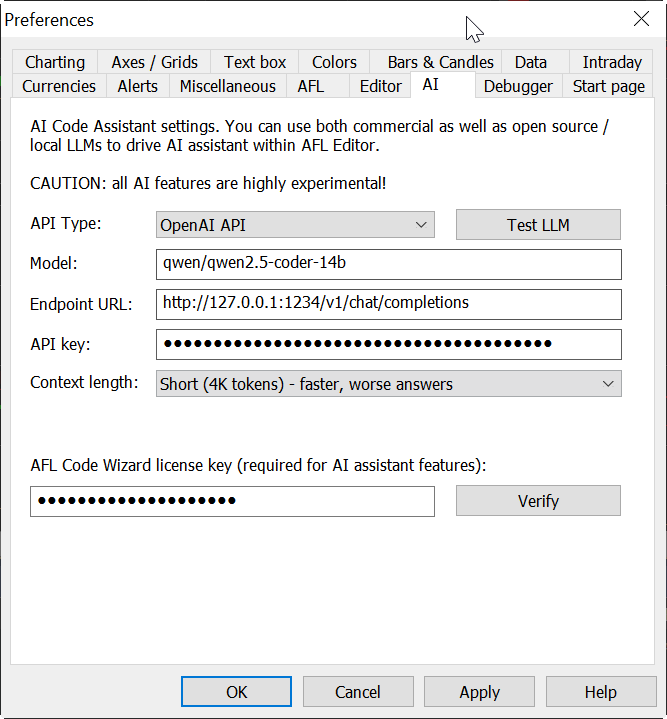
At the end you need to decide whenever you want to use "Short" (about 4K tokens) or "Long" (about 32K tokens) context length. The difference is that when you choose "Long" context, significantly more information is fed into LLM (including full function reference) and that enables way better responses. The tradeoff is the speed. Long context means slower response. It also means more VRAM use in case of local LLM. During our own testing we found that for local LLM it is rather impossible to use Long context. On the other hand Long context works absolutely great with fast and capable cloud-based models like gemini-2.5-flash
After you configured everything as above, now it is time to test if it works at all. You should press Test LLM button. If everything is setup properly you should see message similar to this (text may vary depending on LLM used):
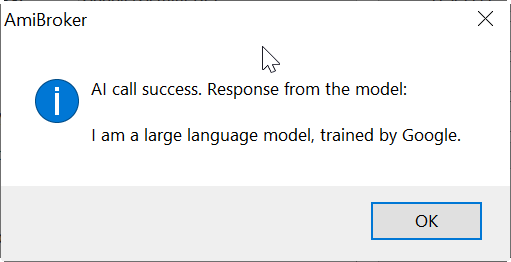
If something went wrong, you will see an error message with explanation what the error is.
The final step is entering AFL Code Wizard License Key in the respective field:
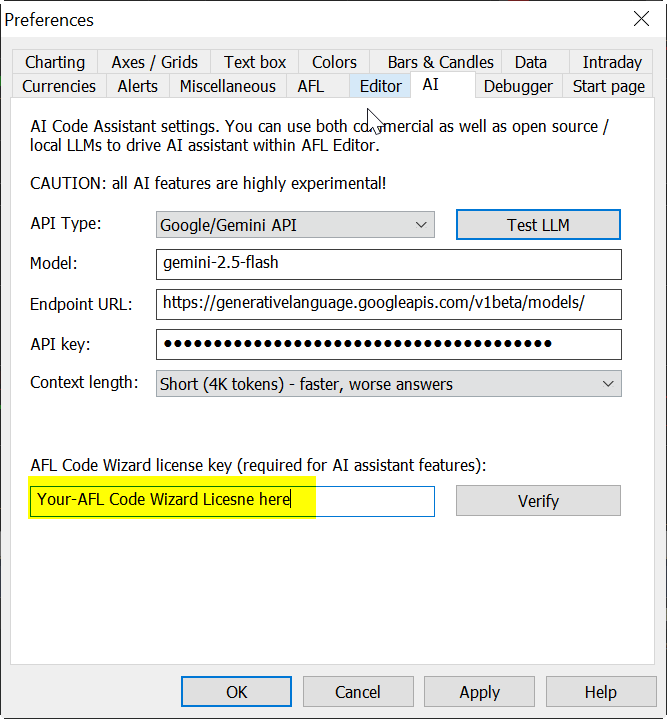
Anyone who has AFL Code Wizard already installed and registered will have the license key prefilled. If you don't have a key, you would find it either in "AFL Code Wizard registration" email or, if you purchased AmiBroker ULTIMATE PACK, in "AmiBroker registration" email. Note that AFL Code Wizard license is separate from AmiBroker (unless you purchased Ultimate Pack).
If you don't have AFL Code Wizard license and don't want to purchase the ability to use AI Assistant in AFL Code Editor will be limited to 5 completions/responses per run.
Depending on which route you choose there might be extra costs involved in using AI features. Running local LLM gives you cost-free solution (not counting the fact that you pay electricity bills and you need to have machine with dedicated graphic card). Runing cloud-based AI typically involves paying fees for inference to the AI/LLM vendor. Pricing depends on model that you choose and number of tokens used. AmiBroker doesn't use much tokens as it does NOT accumulate chat history, therefore it only sends current request/question plus content of the formula plus system prompt (user-selectable either 4K tokens or 32K tokens). To simplify things, token can be seen more or less a "word". Open AI pricing is here: https://openai.com/api/pricing/ , Gemini pricing is here: https://ai.google.dev/gemini-api/docs/pricing Pricing is typically per million tokens so OpenAI 4.1 mini with 0.02 per single request/completion using long context.
Google is even better as it has absolutely great "free tier" that costs nothing and allows for example with Gemini 2.5 Flash model upto 10 requests per minute, 250000 tokens per minute and 250 requests per day.
There are huge differences in performance between various models. We have seen very good results and fast completions with Gemini 2.5 Flash and "Large" context. Still it can take even 30 seconds if Google servers are particularly busy and the task to do is complex.
Using "Short" prompt makes things ~3x faster, but at the expense of quality of response.
While state-of-the-art models from Google and OpenAI work quite well, certain open source models (especially smaller than 12B params) struggle to follow instructions and system prompt and will NOT work at all or work poorly.
As far as private LLMs are considered, we had average success with qwen2.5-coder-14b that is open-weight model specifically trained for coding. Your mileage with open-weight models will vary a lot from being unusable at all to average. Currently open-weight models are nowhere near state of the art when it comes to AFL writing capabilities.
We have done months of extreme prompt tweaking, experiments to steer these models to co-operate and understand not-obvious aspects of AFL. Please treat those new AI features are work-in-progress as models evolve so our prompting techniques evolve too and we can expect improvements in the future.
Last, you might wonder, which model I like the most and I can definitely say Google Gemini 2.5 family of models are currently best in both performance and coding ability.